最近心力略有憔悴,感情未进,家事难断。罢了,如是知,如是见,如是信解。写点文字放松一下🙃,这篇文章来讲讲合批。
合批对于游戏客户端程序已经是老生常谈了,这里简要整理一下合批的一些知识。首先我们来聊一聊Draw Call…
Draw Call
Draw Call是什么?Draw Call实际上就是一个命令,CPU通过调用这个命令来通知GPU进行渲染。对于OpenGL来说,Draw Call就是glDrawArrays、glDrawElements等函数的调用。那么,DrawCall是如何影响性能的呢?作为拷贝忍者卡卡西,这里引用一滴血的记忆的专栏文章
当每次调用API的时候,背后其实都需要经历这么几个阶段:application->runtime->driver->gpu。每一步都存在性能消耗。前三步是在CPU中进行的,而最后一步的gpu消耗主要是在vertex shader、fragment shader、framebuffer中的各种操作(blend、test)。
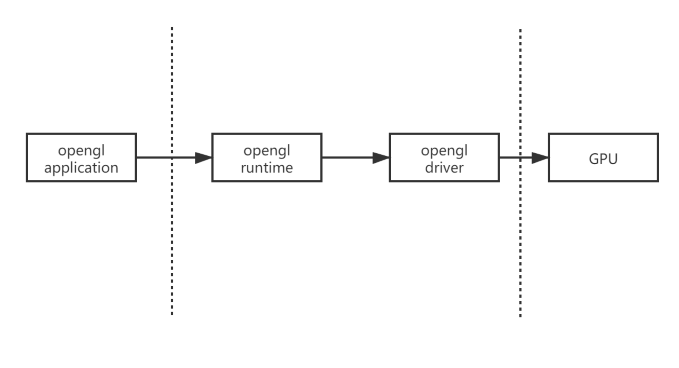
每调用1次渲染api并不是直接经过以上的所有组件通知gpu执行我们的调用。runtime会将api调用转换为设备无关的”命令”(这样才能保证在任何设备硬件上兼容,其实也就是做到对不同的硬件架构做到透明),然后将命令缓存到commandbuffer中去。而命令从runtime到driver这个过程中,cpu会发生从用户模式到内核模式的转换。这个操作是一件非常耗时的工作。所以说如果每次api调用都直接发送命令到driver,那将是非常巨大的性能消耗。所以在不是必须要马上提交给GPU绘制的命令,我们可以先缓存在commandbuffer中,等到需要时一次性提交,优化效率。
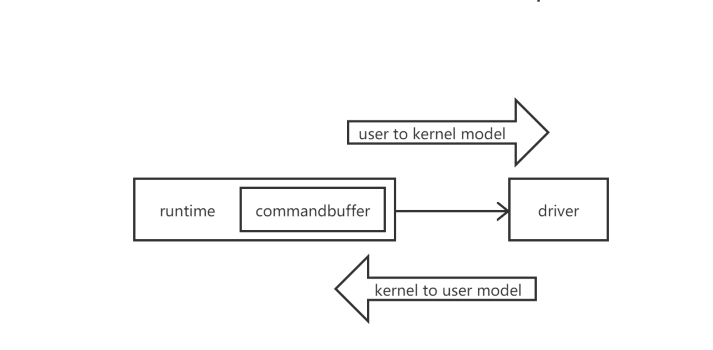
当然这里边还涉及到渲染状态(texture、shader、material各种参数)的影响,如果渲染状态改变了,那么要使用之前渲染状态进行渲染的所有drawcall命令必须全部被执行了。也就是说之前缓冲在commandbuffer中的所有drawcall命令必须刷新。这其实会发生一次从用户模式到内核模式的切换。
从以上两点来看每次渲染状态的改变导致cpu消耗增加其实包含着两个方面的性能消耗:
- runtime需要将api转换成设备无关的”命令”的时间消耗;
- 状态切换导致的从用户模式到内核模式的模式切换的时间消耗。
同样的对于优化batch,减少drawcall也有两条路可走:- 对driver进行优化,使其在转换上降低开销。目前的最新api接口,比如vulkan,metal其实在这方面已经做了很大的改进,大大降低了模式转换上的开销。
- 通过合批降低drawcall,这也是我们唯一能做的手段。
Draw Call消耗很少,渲染状态改变消耗大,毕竟状态改变的情况下会发生用户模式到内核模式的转换。一般情况下Draw Call数量等于渲染状态次数,所以合批(Draw Call Batching)的重要性不言而喻。
cocos2dx中的合批
Auto Batching
cocos2dx 3.0提供了一种叫做自动批绘制(Auto Batching)的技术,对多个相邻的RenderCommand,如果它们使用相同的纹理、相同的blendfunc设置、相同的Shader程序,则只会调用一次OpenGL ES绘制命令。
在主线程遍历完UI树,并将每个UI元素的绘制发送到绘制栈上,绘制线程开始执行全部绘制命令。此时,Renderer需现对RenderCommand进行排序,然后再按照排序后的顺序分别执行绘制命令。
- 当第一次遇到第一个QuadCommand时不会立即绘制,而是将它放入一个数组中缓存起来,然后继续迭代后面的RenderCommand;
- 如果之后遇到的还是QuadCommand,并且它们有相同的materialID(通过对着色器名称、纹理名称、混合方程等相关参数进行Hash计算),则继续添加到缓存数组;
- 如果遇到的RenderCommand类型不是QUAD_COMMAND或者materialID不同,则先绘制之前缓存的QuadCommand数组。
需要注意的是,所有顶点数组使用的是同一个VBO对象,它能容纳的最大Quad数量是10922(65536/6)。所以,当Quad的数量大于这个值的时候,将会立即执行前面的命令。
SpriteBatchNode
SpriteBatchNode比较古老,我们只需要将要绘制的Sprite添加到一个SpriteBatchNode下,引擎会自动帮我们实现批绘制。通常情况下,应用程序中使用的精灵都应该使用Sprite的自动批绘制。
合并与剔除
对于一些可以批渲染的对象,会因为中间插入了其它对象的渲染而打断批渲染,可以通过一个画布对象(Google不到,应该是内部引擎做了扩展)将对象的渲染逻辑抽离出来由画布管理,避免打断批渲染,从而减少Draw Call。
这里有两种策略。一种是合并,将需要批渲染的对象的渲染逻辑抽离出来;另一种是剔除,将打断批渲染的对象的渲染逻辑抽离出来。
Unity中的合批
Unity提供了三种批次合并的方法,分别是Static Batching,GPU Instancing和Dynamic Batching(简要介绍一下,之后补坑)
Static Batching
Static Batching,将静态物体集合成一个大号vbo提交,但是只对要渲染的物体提交其IBO。
Dynamic Batching
Dynamic Batching,将物体动态组装成一个个稍大的vbo+ibo提交。这个过程不要求使用同样的mesh,但是也一样要求同样的材质。
GPU Instancing
GPU Instancing,只提交一个物体的mesh,但是将多个使用同种mesh和material的物体的差异化信息(包括位置,缩放,旋转,shader参数等(shader参数不包括纹理))组合成一个PIO提交。在GPU侧,通过读取每个物体的PIO数据,对同一个mesh进行各种变换后绘制。
合图
合图,也就是合成图集(Texture atlas)。引用wiki中的相关介绍:
In computer graphics, a texture atlas (also called a sprite sheet or an image sprite) is an image containing multiple smaller images, usually packed together to reduce overall dimensions.[1] An atlas can consist of uniformly-sized images or images of varying dimensions.[1] A sub-image is drawn using custom texture coordinates to pick it out of the atlas.

简单来说,图集是包含许多小图的一张大图,它会被GPU视为一个单元。这样,通过增加内存位置后,可以减少渲染状态切换的开销。合图后,CPU在传送资源信息给GPU时,只需要传这张大图就可以了,GPU可以在这张大图中的不同区域进行采样。
当然,图集太大的话,加载这张大图就会出现问题,这就涉及到图集的整理策略。不同的项目有不同的策略,这里不做展开,贴一篇知乎专栏文章【unity游戏开发】图集整理策略。